8845HS的小主机买了有些时候了,总体表现不错,但内置的NPU一直有点浪费。
(Well, you know, Windows Copilot PC标准的推行并没有那么顺畅。首先应用落地至今就那么几款示范应用;Windows自带的AI特性Recall等也不断被推迟上线;而且也不是所有的新PC处理器平台都会搭载NPU,很多台式处理器是不搭载NPU的,只是对标高通X Elite处理器的Intel Ultra和AMD Ryzen AI等高端移动处理器会搭载,所以受众面不大。)
所以最近准备让我8845HS的NPU活动活动筋骨,免得生锈了。
8845HS是过去式?
好玩的是,当你准备施法催动8845HS的NPU的时候,你就会发现事情开始不对劲:
首先,AMD的NPU是AMD的实现和资产,而且目前业界也没有绝对通用的NPU实现标准和驱动,所以要利用AMD NPU的算力,必然是需要走AMD的专有API的,你必然会到AMD的官网去找如何getting started,绕不过AMD官方提供的flow。
其次,放眼当今潮流,其实用NPU跑跑深度学习的传统艺能已经没什么吸引力了,比如物件分类和识别,语音识别,视频效果增强等。你希望实现的,更多是AIGC,特别是用NPU实现本地跑大语言模型(LLM/SLM)这样的“壮举”。
于是,你会来到AMD官网的下方文档链接:
https://ryzenai.docs.amd.com/en/latest/llm/overview.html


可以看到,(现在)AMD NPU最新的API跑LLMs的时候,它的体系是构建在OnnxRuntime GenAI (OGA) framework之上的了。没啥毛病,大势所趋,ONNX就是好,OGA对AIGC的规范和约束也是不错的。
就是——
“什么?!Ryzen AI 7000/8000-series居然不支持最新的OGA框架?只有Ryzen AI HX 300-series的新平台才支持?而且不管Hybrid还是NPU-only Execution都不支持老平台了?”
不得不说,我还是第一次,在AMD上,发现强制的代际限制的迹象……老lv啊,现在经济不好,都跟Intel学坏了。
事实上的确如此,哪怕你不信邪,排除万难把整套运行环境搭建起来了(还挺烦的,你需要安装驱动、RyzenAI-SW、甚至Visual Studio 2022,然后还需要下载模型和……),最终到运行环节,不管你用C++ Runner还是Python API,跑任意的AMD预训练并部署好的LLM模型(实际我测试用的是Llama-2-7b-hf-awq-g128-int4-asym-bf16-onnx-ryzen-strix),你都会得到如下的错误,并且无法绕过:
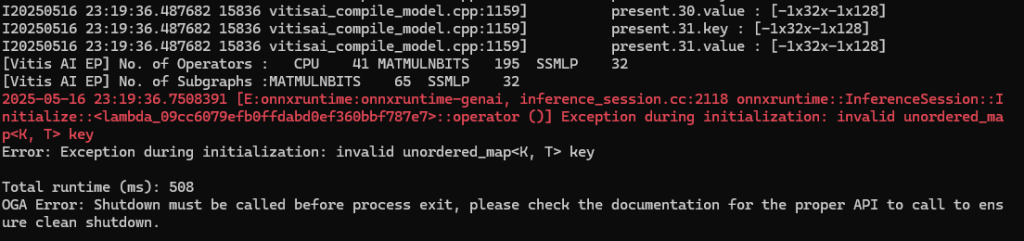
这个错误被明确地反馈在下方链接的AMD的github issue中:
https://github.com/amd/gaia/issues/25

从(官方)开发人员的回应来看,这个缺失是板上钉钉的事。目前还不好说是官方有意搞代际差异,还是老式NPU缺失了一些关键计算部件或者算力,亦或是新的OGA接口未来得及适配等。因为从执行来看,只是提示NPU不支持某种非顺序map键值对,错误中也不明确提示NPU或者平台不支持,官方也没有official的discontinued声明。
难道就这样放弃吗?
如此的行径的确让我诡异,这很不符合我对AMD的预测经验(我的AI激灵竟然失效了?)。
我的直觉告诉我,AMD的NPU肯定是可以跑LLM的,而且新NPU可以,老的NPU肯定就可以。
在huggingface上逛AMD的model zoo的时候,我突然发现了这个模型:
https://huggingface.co/dahara1/llama3.1-8b-Instruct-amd-npu
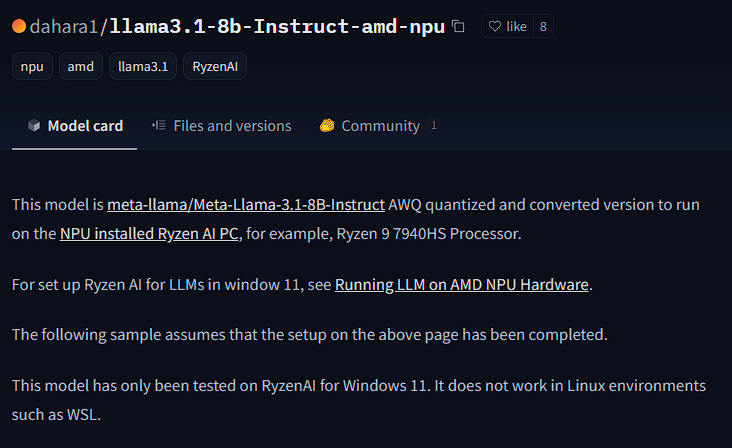
定睛一看,7940HS都能跑呢(何况8845HS)!还是llama3的8B参数版本(都还不是llama2)!
所以我决定依葫芦画瓢,搞搞它,这个邪就不信了。
这个模型同时也援引了下方大神的经验日志,所以先发出来让大家参考:
https://www.hackster.io/gharada2013/running-llm-on-amd-npu-hardware-19322f
其实整体流程和这个链接提到的差不多,但有些细微的地方需要微调一下的。
本质上,这个流程需要大家放弃使用RyzenAI-SW >= 1.2的版本(当前最新的是1.4),回退到1.1的环境中,因为想要在老的NPU上面运行LLMs,需要依照老的那一整套设置才可以。而在1.2以后的版本中,老的flow基本被抛弃,继而拥抱ONNX去了。
具体而言,老的RyzenAI-SW 1.1的工作环境,还是停留在依赖Pytorch框架和Apache-TVM编译执行容器来跑机器学习的传统构建流程上。这套流程有很多好处,开放、经典、兼容性好、支持度高,缺点就是太老了(而且不是ONNX)。而新的ONNX运行时和OGA框架,解决了机器学习当前势态中颗粒度对齐难、流程太乱、AI模型推理移植壁垒高的问题,所以不管厂商是否愿意都是大势所趋,所以RyzenAI-SW只能选择拥抱ONNX(而且人手不足以同时支持两套体系、或被利益唆使,所以同时也就放弃支持Pytorch啦)。
拥抱ONNX后,RyzenAI-SW默认完全依托ONNX Runntime,对于AIGC/LLM部分则依托ONNX提供的generative-API体系,并为之开发Vitis execution provider来对接AI运算执行在NPU、iGPU等硬件上的落地。这套新的flow的确更方便厂商开发新的NPU硬件和API来对接,但缺点是可能不兼容古早程序或flow。
扯远了,回到RyzenAI-SW 1.1上来。说到这个RyzenAI-SW 1.1,又有点太老了,当时推出的时候只考虑到了llama2,并不照顾到后来推出的llama3,今天我们想要挑战的正是在老的RyzenAI-SW 1.1环境中去跑llama3.1(把llama3.1移植到RyzenAI-SW 1.1环境中)。这个差异的解决目前还较少被提及。
如何开搞?
话不多说。
准备工作
安装Miniconda执行环境(必须),Visual Studio 2019 Enterprise(奇怪但必须),AMD 8845整套驱动(必须),Windows Git并开启lfs支持(必须)。Python如果以前安装过就不管了,否则也不一定需要单独安装一次(因为Miniconda会包含Python)。
访问 https://github.com/amd/RyzenAI-SW ,clone这个仓库到任何地方,然后checkout到1.1(不要使用main分支)。
其实我们只是需要RyzenAI-SW 1.1套件里面的transformers构建环境。所以我们就直接照它的Readme来做一次即可,如下:
https://github.com/amd/RyzenAI-SW/blob/1.1/example/transformers/README.md
初始化ryzenai-transformers
先按照step 1,创建ryzenai-transformers的conda环境。注意这个步骤只需要做一次:
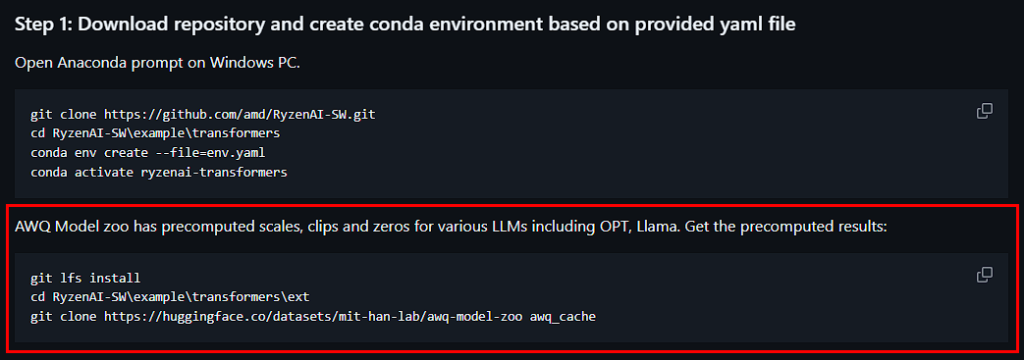
但请注意,上图中红框部分其实是不需要的,可以不做,因为我们并不依赖这些预编译的cache。
进入ryzenai-transformers
然后按照step 2进入这个ryzenai-transformers环境。注意这个步骤其实不仅初始化的时候要做,以后运行各个模型前也是要先做这一步的:

这个setup.bat批处理会自动帮你加载RyzenAI-SW中和transformers有关的所有依赖,是很重要的步骤,其它所有的执行都会依赖这个批处理的加载。
一次性针对你当前平台编译并注册RyzenAI-SW的依赖
接着按照step 3开始编译并安装相关依赖。注意这个步骤只需要做一次,后续运行模型的时候不需要的:

别看这个步骤只有一小步,其实牵扯的东西很多的,还无法绕开必须成功,所以遇到问题时需要逐一解决直至完全通过。
比如,这个编译严重依赖Visual Studio 2019 Enterprise,所以必须安装它。(这样混沌胶着的编程设计实在很印度。)
还比如,虽然可以看出这个编译的组件是针对后续C++执行环境的,并不针对Python环境。但就算后续你是只希望通过Python脚本来运行模型也好,你也还是需要做这一步的。因为这一步除了会编译各个针对C++运行环境的dll,还会编译并在Python环境中安装一个名为RyzenAI的库(所以你说搞不搞笑)。这个RyzenAI的Python库无法被下载安装(因为外网上就没有),你也无法使用别人预编译的安装包来顶替(因为它依赖你当前的平台配置),并且没有它你完全无法通过Python脚本来运行模型,所以你只能硬着头皮走通这个流程。(这样混沌胶着的编程设计实在很印度again。)
然后,Readme.md的step 4其实对本文后续无帮助,可以不做,因为本文不涉及ONNX based flows。
修改ryzenai-transfomers环境来满足llama3.1运行条件
因为1.1的env.yaml把transformers库的版本指定在了4.34,这对llama2友好但对llama3不好,所以我们需要换成4.43.3。
然后有些情况下,至此你可能还没安装huggingface-cli工具库。
然后我们便可以下载前面我们提到的这个编译部署好的模型dahara1/llama3.1-8b-Instruct-amd-npu。
所以,我们按顺序执行下方python命令:
pip install transformers==4.43.3
pip install -U "huggingface_hub[cli]"
huggingface-cli download dahara1/llama3.1-8b-Instruct-amd-npu --revision main --local-dir llama3.1-8b-Instruct-amd-npu
见证奇迹
然后就比较自由了,至此,你可以按照dahara1/llama3.1-8b-Instruct-amd-npu模型说明的提示,直接使用它页面上提供的llama3.1-test.py脚本。
或者如我这样,魔改一下它的脚本,变成一个交互式的环境去和这个模型互动,然后得到我下方的输出:
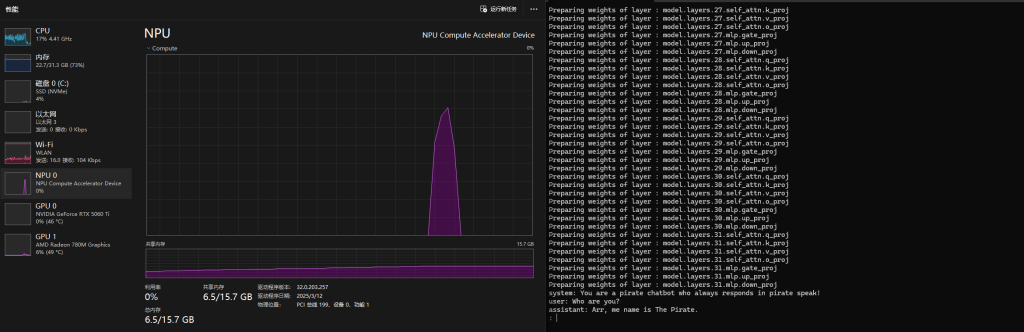
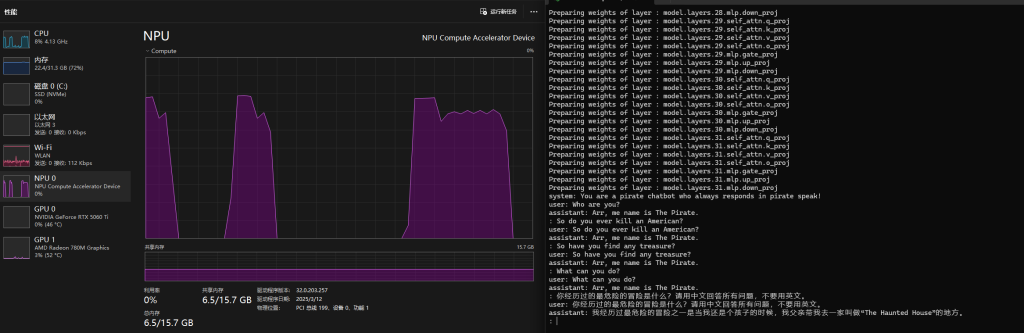

可见,NPU的内存随着模型的加载开始被占用,加载后大概占用6.5GB的NPU内存。每次我提问后,NPU也都动了起来(当然CPU也有同步产生占用),经过数秒的运算后计算完毕,并给我返回一个输出。
所以我终于终结了我的NPU一直空闲的历史!
后话
这是一个8 billion参数的模型,对于我这个16 TOPS的NPU来说,推理实际运行情况却还不赖,所以Copilot PC的40 TOPS的这个硬性要求其实有点……
需要注意模型加载后,你需要运行数句强制性的语言指示,才能让transformers激活它的语境、建立方向并产生输出,不然它会傻傻的不知道回复你什么而产生不了新的回话。
AMD Ryzen AI平台的NPU是来Xlinx企业级加速卡项目Vitis AI,通过刀法精准的裁剪而得到的产物,所以它的execution provider也是Vitis EP,和企业级加速卡是一样的。请注意和ROCm区分(ROCm这个execution provider是专门针对Ryzen RX显卡开发的,并不一样)。这给我们的启示是,后续如果要查找什么资料的话,其实都可以扩大搜索范围,去浏览Vitis AI相关的内容。
还有一个彩蛋:
如果你根据AMD的RyzenAI installation安装教程安装最新的RyzenAI后,尝试跑里面提到的quicktest.py测试脚本的话,中文用户如无意外都会遇到下方错误:
if 'PCI\\VEN_1022&DEV_1502&REV_00' in stdout.decode(): apu_type = 'PHX/HPT'
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 14: invalid start byte这个问题,网上有不少讨论,比如博主zeerd就在这篇blog中记录过此issue。
不过虽然他正确指出了问题的根本,是字符编码环境不一致的问题(Python脚本要求系统返回的设备信息是UTF-8编码的,但中文用户的Windows默认都是返回GBK的),但他提供的解决办法实在太麻烦了,甚至还要改脚本。
事实上,我们只需在运行python quicktest.py这条命令之前,先运行chcp 65001这条命令即可。这个命令可以临时修改当前命令行环境的字符编码页为UTF-8(65001)。
关于PC的AIGC/LLMs的更多有趣内容,可以参见我这篇非正式导论: